
Recent days I got curious that what topics attract most of economists' attentions. NBER working paper series contain some relatively new research fruits so I used it as the raw input.
It is not hard to extract key words from these papers' titles. After that, I made a further step that matched all single keys to academic keywords on Microsoft Academic.
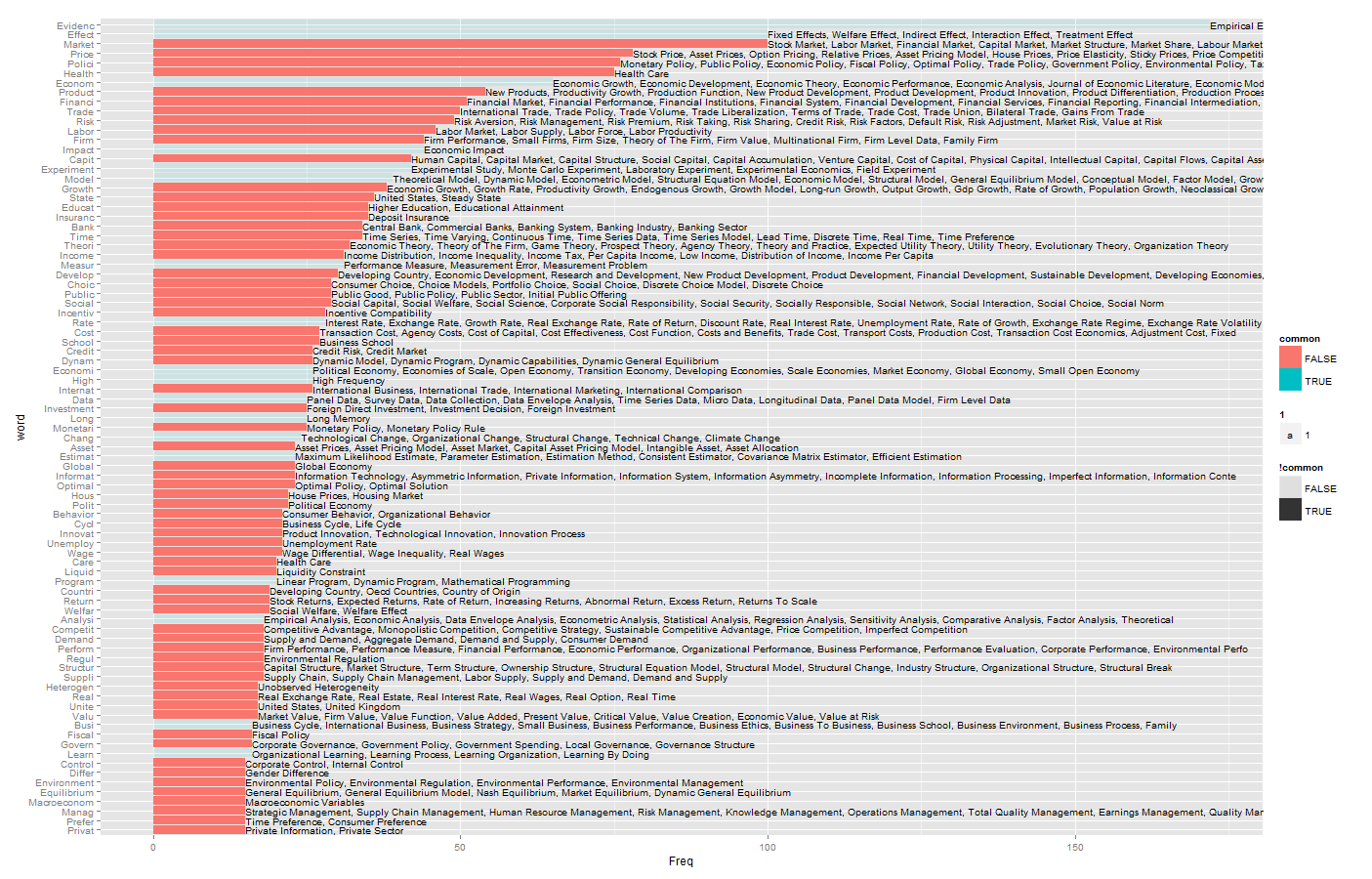
From a glance, I manage to identify some hot keys:
Price. Health. Social. Policy/Public. Risk/asset/liquidity. Growth. Insurance. Education/School.
For reproducible purpose, my code is here.
grab_url <- c("http://www.nber.org/new_archive/mar14.html",
"http://www.nber.org/new_archive/dec13.html",
"http://www.nber.org/new_archive/sep13.html",
"http://www.nber.org/new_archive/jun13.html",
"http://www.nber.org/new_archive/mar13.html")
library(RCurl)
require(XML)
grab_paper <- function (grab) {
webpage <- getURLContent(grab)
web_content <- htmlParse(webpage,asText = TRUE)
paper_title <- sapply(getNodeSet(web_content, path="//li/a[1]"),xmlValue)
author <- sapply(getNodeSet(web_content, path="//li/text()[1]") ,xmlValue)
paper_author <- data.frame(paper_title = paper_title, author = author)
return(paper_author)
}
library(plyr)
paper_all <- ldply(grab_url,grab_paper)
titles <- strsplit(as.character(paper_all$paper_title),split="[[:space:]|[:punct:]]")
titles <- unlist(titles)
library(tm)
library(SnowballC)
titles_short <- wordStem(titles)
Freq2 <- data.frame(table(titles_short))
Freq2 <- arrange(Freq2, desc(Freq))
Freq2 <- Freq2[nchar(as.character(Freq2$titles_short))>3,]
Freq2 <- subset(Freq2, !titles_short %in% stopwords("SMART"))
Freq2$word <- reorder(Freq2$titles_short,X = nrow(Freq2) - 1:nrow(Freq2))
Freq2$common <- Freq2$word %in% c("Evidenc","Effect","Econom","Impact","Experiment","Model","Measur","Rate","Economi",
"High","Data","Long","Chang","Great","Estimat","Outcom","Program","Analysi","Busi"
,"Learn","More","What")
library(ggplot2)
ggplot(Freq2[1:100,])+geom_bar(aes(x=word,y=Freq,fill = common,alpha=!common))+coord_flip()
### get some keywords from Bing academic
start_id_Set = (0:5)*100+1
require(RCurl)
require(XML)
# start_id =1
#
get_keywords_table <- function (start_id) {
end_id = start_id+100-1
keyword_url <- paste0("http://academic.research.microsoft.com/RankList?entitytype=8&topDomainID=7&subDomainID=0&last=0&start=",start_id,"&end=",end_id)
keyword_page <- getURLContent(keyword_url)
keyword_page <- htmlParse(keyword_page,asText = TRUE)
keyword_table <- getNodeSet(keyword_page, path="id('ctl00_MainContent_divRankList')//table")
table_df <- readHTMLTable(keyword_table[[1]])
names(table_df) <- c("rowid","Keywords" , "Publications" ,"Citations")
return (table_df)
}
require(plyr)
keywords_set <- ldply(start_id_Set,get_keywords_table)
save(keywords_set, file="keywords_set.rdata")