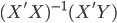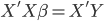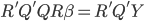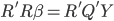It took me a while to come up with the best title to describe my past 15 days experience in Israel... Finally I was inspired by "full of ingredients" and just a little change -- full of adventures.
I think I am the kind of person who loves to travel alone. I seldom make a travel plan -- last time when I traveled to Tibet and Nepal I didn't even book a round-way ticket. That's the unpredictable part of traveling: I don't know what's going to happen, so everything is a surprise and I enjoy the process of discovery.
This time to Israel was in fact better organized. It was a business trip; otherwise it would be very hard for me to get a visa to Israel. I had to stay in office on workdays; but that was not too bad either, because I could chat with Israeli colleagues and learn from them. Of course weekends were my adventure time.
600 KM Drive
The most remarkable day was the second Friday (Sunday-Thursday are workdays in Israel), when I drove 600 km by myself up to the north. Haifa, Sea of Galilee, Golan Heights. I watched the most beautiful moon-rise in my life when the moon rose up from mountains over the Galilee Sea. I could not stop myself from constantly driving around Sea of Galilee until the sky went completely dark and my GPS kept correcting me to the right route back to Tel Aviv. It was too amazing to be rational. Time flew without awareness.

Moon rise at the Galilee Sea
When I walked to a Cafe on top of the Bahai Garden for a short afternoon tea, it turned out to be a coincidence that a painter was drawing a painting that very similar to me! I wish I was in a long light dress so I could have matched the painting much better!
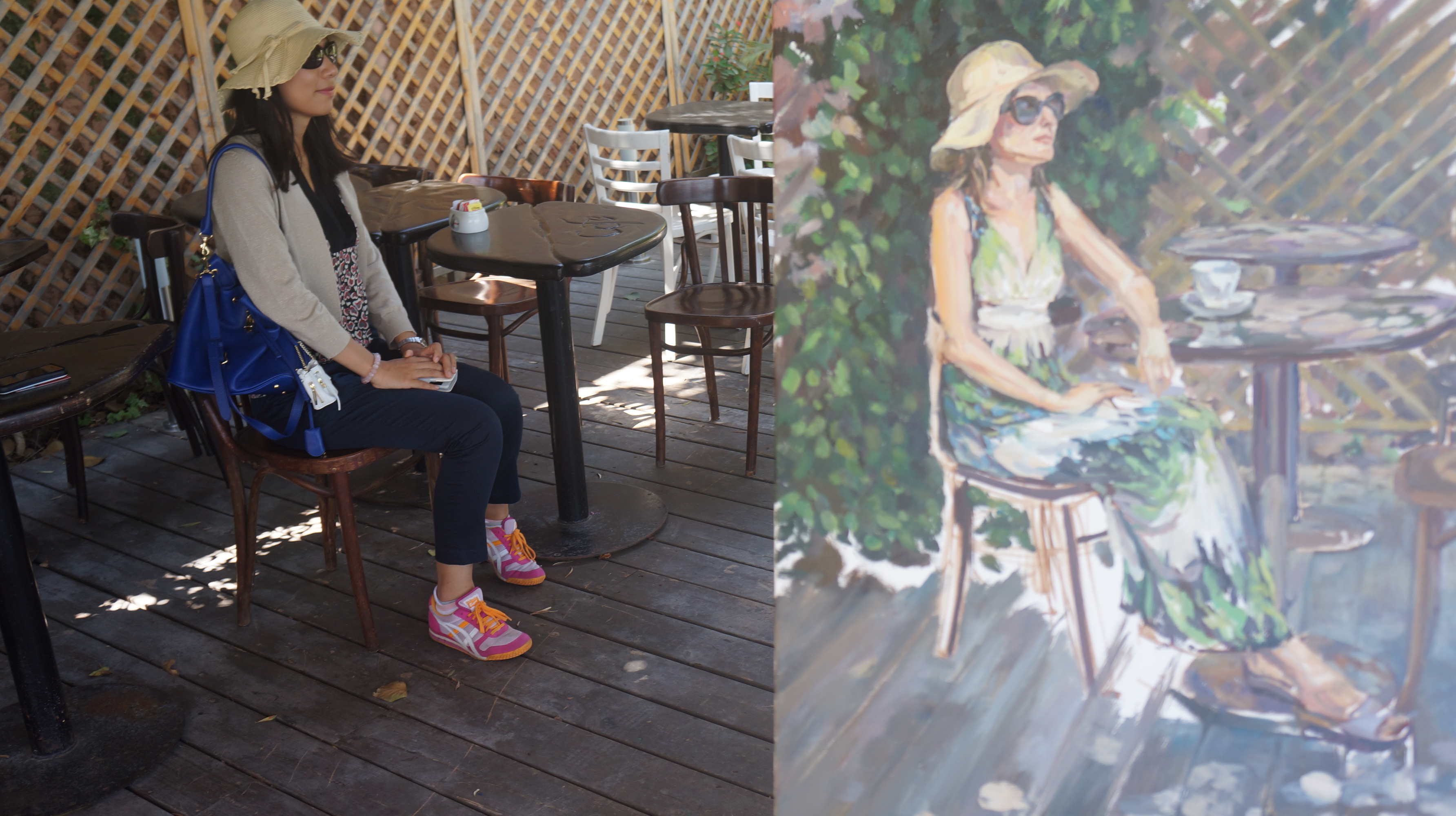
Coincidence!

The painter and her painting.